





머니두잇입니다. 일레븐랩스에 관한 영상을 올렸습니다. 내 목소리의 표본이 최소 30분 이상이 필요합니다. 최소 3시간 이기 때문에 1시간이 넘어가면 좋겠지만, 저는 35분에 달하는 최소치만 음성을 모아서 제출하여 제작했습니다. 먼저 느낀 바로는 일레븐랩스의 내 목소리로 커스텀하는 TTS는 제출한 음성들의 말투나 속도까지 모두 카피하는 것으로 보입니다.
아래는 제가 일래븐랩스를 이용하여 ‘전문 음성 복제’로 제 목소리를 음성으로 만들어본 예시입니다. 상당히 유사하다는 것을 알 수 있었고, 음성 표본을 녹음할 때, 조금 더 빠르게 했으면 어땠을까 하는 생각이 있습니다.
- 목소리가 매우 유사합니다.
- 녹음할 당시 속도와 비슷하게 출력합니다.
일레븐랩스의 유료 기능
해당 기능을 사용하려면 일레븐랩스의 유료 기능을 해금해야 합니다. 듣기로는 처음엔 무료였다고 들었습니다만, 사람들이 많아지면서 차츰차츰 유료로 전환한 것이 아닐까 생각이 됩니다.
일레븐랩스 가격표
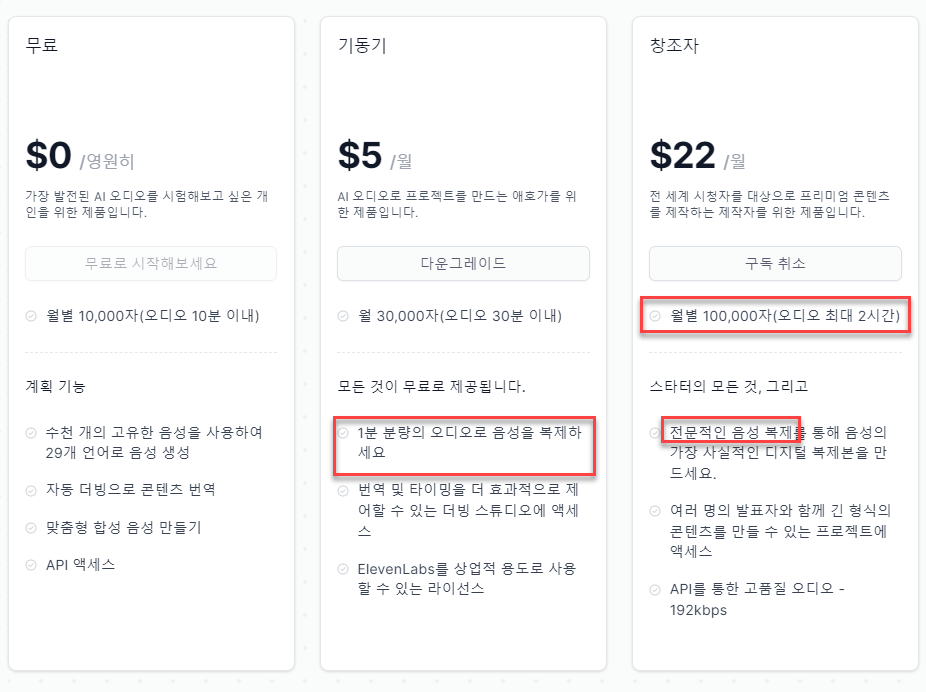
무료에서는 음성 복제 기능을 사용할 수 없습니다. 가동기에선 최소한의 음성 복제가 가능하고, 저처럼 녹음한 음성의 피치, 속도, 말투 등을 복제하려면 전문적인 음성 복제가 필요합니다. 음성 복제용 음원들은 최대한 조용한 환경에서 녹음되어야 하며, 가공을 거쳐 목소리만 잘 들릴 수 있게 깔끔하게 한 뒤 제출하는 것이 좋습니다.
일레븐랩스 가이드
일레븐랩스의 기능들을 정리합니다. 기능들을 아래와 같습니다.
- TTS 기능 – 텍스트를 음성으로 전환합니다.
- 음성 대 음성 – 기존의 음성을 다른 느낌으로 전환합니다.
- 내 목소리 복제 – 목소리를 복제하는 기능입니다. (다른 사람이 만든 목소리를 사용할 수도 있습니다.)
- 더빙 – 기존 음성을 다른 언어로 번역할 수 있습니다.
개인적으로 타입캐스트라는 서비스를 꽤 오래 이용해봤습니다. 하지만 비싼 가격과 개인적으로 만족이 안 되는 성능으로 구독을 끊었습니다. 하지만 일레븐랩스의 현재 가격은 월 22달러로 타입캐스트보다 저렴하면서 더 고급 Ai 기능을 제공하고 있습니다.
TTS 기능 가이드(문장 연설)
최적의 목소리를 찾기 위해서 여러 세팅값을 참고했습니다. Speech라고 적힌 탭을 눌러주면 TTS 기능으로 이동합니다. 거기서 세팅을 눌러 목소리의 정확성을 개선할 수 있습니다.(아직 목소리의 속도는 제어하지 못합니다.)

세팅을 누르면 조절해야 할 값은 5가지입니다. 여기서 집중적으로 살펴봐야 할 것은 Stability와 Similarity입니다. 그리고 다른 기능들에 관한 일래븐랩스의 설명입니다.
안정성(Stability)
안정성 슬라이더는 음성의 안정성과 각 생성 간의 무작위성을 결정합니다. 이 슬라이더를 낮추면 음성의 감정 범위가 넓어집니다. 앞서 언급한 바와 같이, 이는 원래 음성에 크게 영향을 받습니다. 슬라이더를 너무 낮게 설정하면 지나치게 무작위적이고 캐릭터가 너무 빠르게 말하는 이상한 음성이 생성될 수 있습니다. 반면에 너무 높게 설정하면 제한된 감정을 가진 단조로운 음성이 될 수 있습니다.
예를 들어, 안정성 슬라이더를 낮게 설정하면 캐릭터가 한 문장 안에서도 다양한 톤과 속도로 말할 수 있습니다. 반면 안정성을 높게 설정하면 문장 전체에 걸쳐 일관된 톤과 속도를 유지하게 됩니다. 적절한 안정성 수치는 원하는 음성 스타일과 캐릭터의 성격에 따라 달라질 수 있습니다.
유사도(Similarity)
유사도 슬라이더는 AI가 원래 음성을 복제할 때 얼마나 충실하게 따라야 하는지를 결정합니다. 원본 오디오의 품질이 좋지 않고 유사도 슬라이더가 너무 높게 설정된 경우, 원본 녹음에 잡음이나 배경 노이즈가 있었다면 AI가 음성을 모방하려고 할 때 그러한 결함을 재현할 수 있습니다.
예를 들어, 원본 오디오가 낮은 비트레이트로 녹음되었거나 마이크 품질이 좋지 않아서 잡음이 많이 섞여 있는 경우, 유사도를 높게 설정하면 AI가 생성한 음성에도 같은 잡음이 들어갈 수 있습니다. 반면 유사도를 낮추면 AI는 원본 음성의 특징을 따르되 잡음은 최소화하여 더 깨끗한 음성을 생성하게 됩니다. 적절한 유사도 수치는 원본 오디오의 품질과 원하는 음성의 충실도에 따라 조정할 수 있습니다.
스타일 과장(Style Exaggeration)
새로운 모델의 도입과 함께 스타일 과장 설정도 추가되었습니다. 이 설정은 원래 화자의 스타일을 증폭시키려고 시도합니다. 0 이외의 값으로 설정하면 추가적인 연산 자원을 소모하고 지연 시간이 증가할 수 있습니다. 이 설정을 사용하면 모델이 원래 음성의 스타일을 강조하고 모방하려고 하기 때문에 약간 불안정해질 수 있다는 점에 유의해야 합니다.
일반적으로 우리는 이 설정을 항상 0으로 유지할 것을 권장합니다.
예를 들어, 원본 음성이 매우 특이한 억양이나 말투를 가지고 있는 경우 스타일 과장을 높게 설정하면 AI가 그 스타일을 지나치게 모방하여 부자연스러운 음성이 생성될 수 있습니다. 반면 스타일 과장을 0으로 설정하면 AI는 원본 음성의 스타일을 자연스럽게 따르되, 과장되지 않은 자연스러운 음성을 생성하게 됩니다. 대부분의 경우 스타일 과장 설정은 0으로 유지하는 것이 안정적이고 자연스러운 음성을 얻는데 도움이 됩니다.
화자 부스트(Speaker Boost)
이것은 새로운 모델에서 도입된 또 다른 설정입니다. 설정 자체는 매우 직관적입니다. 원래 화자와의 유사성을 높여줍니다. 그러나 이 설정을 사용하면 약간 더 높은 연산량이 필요하므로 지연 시간이 증가합니다. 이 설정으로 인한 차이는 일반적으로 상당히 미묘합니다.
예를 들어, 원본 화자의 목소리가 약간 독특하거나 특이한 경우 화자 부스트를 높이면 AI가 그 특징을 더 잘 모방할 수 있습니다. 하지만 화자 부스트를 너무 높이면 오히려 부자연스러워 보일 수 있으며, 음성 생성에 더 많은 시간이 소요됩니다. 대부분의 경우 화자 부스트를 적절한 수준으로 설정하면 원본 화자와의 유사성을 높이면서도 자연스러운 음성을 얻을 수 있습니다.
TTS(Speech) 최적 세팅
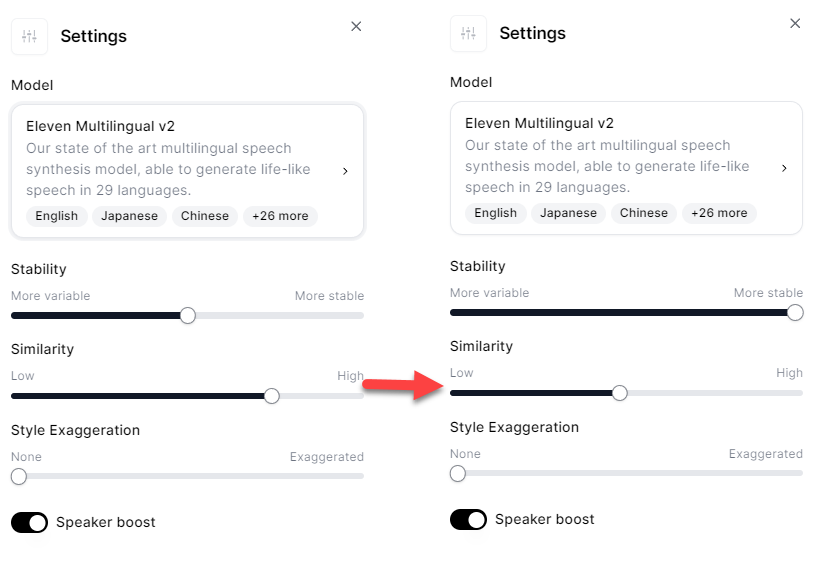
머니두잇이 찾아낸 최적의 세팅값입니다. 모델은 최신 모델인 일레븐랩스 멀티랭귀지 v2 버전은 기본으로 하고, 안정성은 100%로 올린 상태에서 유사도는 50% 정도로 설정합니다. 어떤 목소리를 활용하는지에 따라 세팅이 조금씩 달라질 수도 있습니다.
히스토리(history)
일레븐랩스에서 히스토리 탭을 클릭하면 여태 만들었던 모든 TTS를 확인하고 다운로드 받을 수 있습니다 연설(Speech) 탭에서 확인할 수 있습니다.

더빙 가이드
메뉴에서 더빙을 눌러줍니다. 그런 다음 기존에 만들어진 음성을 선택하고, 다른 언어로 더빙할 수 있습니다. 성능은 아직 완벽하지는 않습니다만, 비슷한 목소리로 비슷하게 만들어낼 수 있습니다.
언어 선택을 동시에 해서 여러 영상을 동시에 번역할 수 있습니다. 더빙할 때 필요한 문장의 수는 1분당 2000단어가 소모됩니다. 기존의 22달러 요금제의 경우에는 TTS가 10만자를 제공합니다. 대략 50분 가량을 더빙한다면 10만자를 모두 소비하게 됩니다.