





양자화는 머신러닝, 특히 딥러닝 분야에서 사용되는 모델 압축 기술 중 하나입니다. 모델의 가중치(weight)를 표현하는 데 사용되는 비트 수를 줄여서 모델의 크기를 감소시키는 방법입니다. 일반적으로 딥러닝 모델의 가중치는 32비트 부동소수점(FP32) 형식으로 저장됩니다. 양자화는 이 가중치를 더 낮은 비트 수, 예를 들어 8비트 정수(INT8) 또는 4비트 정수(INT4)로 근사하는 과정입니다.
양자화 과정은 다음과 같이 이루어집니다:
- 가중치의 범위를 분석
- 가중치를 일정한 구간으로 나눔
- 각 구간을 정수 값으로 매핑
- 가중치를 매핑된 정수 값으로 대체
이렇게 하면 가중치를 표현하는 데 필요한 비트 수가 줄어들어 모델의 크기가 감소합니다. 양자화된 모델은 추론 시에 정수 연산을 사용하므로 계산 속도도 빨라질 수 있습니다.
양자화는 약간의 정보 손실을 동반하지만, 많은 경우 모델의 성능에 미치는 영향이 크지 않습니다. 따라서 양자화는 모델 압축과 최적화를 위해 널리 사용되는 실용적인 기술입니다.
양자화랑 양자역학이랑 뭔 관계임?
양자화(Quantization)는 양자역학과는 직접적인 관련이 없습니다.
양자화 Q4와 Q8의 차이
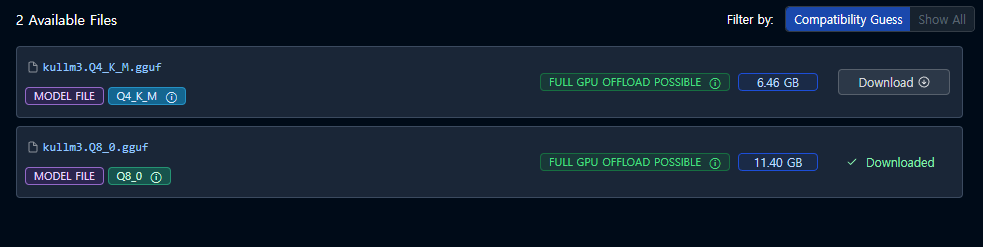
LM 스튜디오에선 kullm3.Q4_K_M.gguf과 kullm3.Q8_0.gguf의 차이가 있습니다. 뒤에 보시면 Q4, Q8의 차이가 있습니다.
Q4와 Q8은 DeepSpeed에서 제공하는 양자화(Quantization) 기술의 서로 다른 레벨을 나타냅니다.
Q4는 4-bit 양자화를 의미하고, Q8은 8-bit 양자화를 의미합니다. 양자화는 모델의 가중치(weight)를 더 낮은 비트 정밀도로 표현하여 모델 크기를 줄이는 기술입니다.
- 4-bit 양자화(Q4)는 가중치를 4비트로 표현하므로 모델 크기가 더 작아집니다. 하지만 정밀도 손실이 더 크게 발생할 수 있습니다.
- 8-bit 양자화(Q8)는 가중치를 8비트로 표현하므로 4-bit에 비해 모델 크기는 더 크지만, 정밀도 손실은 상대적으로 적습니다.
따라서 Q4 모델(6.46GB)이 Q8 모델(11.40GB)보다 용량이 작은 이유는 가중치를 더 낮은 비트로 표현했기 때문입니다. 양자화 레벨에 따라 성능과 정확도의 차이가 발생할 수 있으므로, 목적에 맞게 적절한 양자화 레벨을 선택하는 것이 중요합니다.
일반적으로 Q4는 추론 속도와 메모리 사용량이 중요한 경우에, Q8은 모델의 정확도를 어느 정도 유지하면서 크기를 줄이고 싶은 경우에 사용됩니다. 양자화를 적용하면 모델 성능이 다소 감소할 수 있지만, 상당한 크기 절감 효과를 얻을 수 있습니다.
그래서 양자화 해서 얻는 이득은?
VRAM 절약
모델 크기가 작아지면 GPU의 VRAM(비디오 RAM)을 더 적게 사용합니다. 이는 동시에 더 많은 모델을 로드하거나, 더 큰 배치 크기(batch size)로 학습/추론할 수 있게 해줍니다. 또한 VRAM이 제한된 환경에서도 모델을 사용할 수 있게 됩니다.
저장 공간 절약
모델 파일의 크기가 작아지므로 저장 공간을 절약할 수 있습니다. 이는 모델을 저장하고 배포하는 데 드는 비용을 줄일 수 있습니다.
추론 속도 향상
모델 크기가 작아지면 캐시 효율이 향상되고 메모리 대역폭 사용량이 줄어들어 추론 속도가 빨라질 수 있습니다. 특히 임베디드 기기나 실시간 응용 프로그램에서 유리합니다.
에너지 효율 향상
모델 크기 감소는 연산량 감소로 이어지므로, 에너지 소모를 줄일 수 있습니다. 이는 배터리 구동 기기나 대규모 데이터 센터에서 중요한 요소입니다.
네트워크 전송 속도 향상
모델 크기가 작으면 네트워크를 통해 전송하는 데 걸리는 시간이 줄어듭니다. 이는 분산 학습이나 모델 배포 시나리오에서 유리합니다.
다만 모델 크기를 너무 많이 줄이면 성능이 크게 감소할 수 있으므로, 용도에 맞게 적절한 수준의 양자화를 적용하는 것이 중요합니다. 일반적으로 Q8 양자화는 성능 저하를 최소화하면서 모델 크기를 상당히 줄일 수 있는 좋은 선택지로 여겨집니다.
양자화의 종류와 모델 크기 하락폭
양자화에는 다양한 종류와 레벨이 있습니다. 가장 일반적으로 사용되는 것은 8비트(INT8)와 4비트(INT4) 양자화이지만, 이 외에도 다른 비트 수를 사용할 수 있습니다.
- 16비트 부동소수점(FP16) 양자화
- 2비트 양자화(INT2)
- 1비트 양자화(바이너리)
양자화 레벨이 낮을수록(비트 수가 적을수록) 모델 크기 감소 효과가 크지만, 정보 손실도 커집니다. 따라서 양자화 레벨은 모델의 성능과 크기 간의 균형을 고려하여 선택해야 합니다.
일반적으로 FP32에서 INT8로 양자화할 경우, 모델 크기가 약 1/4로 줄어듭니다. INT4로 양자화하면 크기가 1/8로 줄어듭니다. 하지만 실제 압축 효과는 모델 구조와 가중치 분포에 따라 다를 수 있습니다.
예를 들어, FP32 모델이 100MB라면:
- INT8 양자화 후 크기: 약 25MB
- INT4 양자화 후 크기: 약 12.5MB
다만 양자화 레벨이 너무 낮으면(예: INT2 또는 바이너리) 성능이 크게 감소할 수 있으므로, 대부분의 경우 INT8 또는 INT4 양자화를 사용합니다.
양자화와 더불어 가중치 pruning(가지치기), 허프만 인코딩 등의 기술을 조합하면 모델 크기를 더욱 줄일 수 있습니다. 최적의 양자화 레벨은 모델의 용도, 성능 요구사항, 하드웨어 제약 조건 등을 종합적으로 고려하여 선택해야 합니다.